Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
python - Query padding mask and key padding mask in Transformer encoder ...
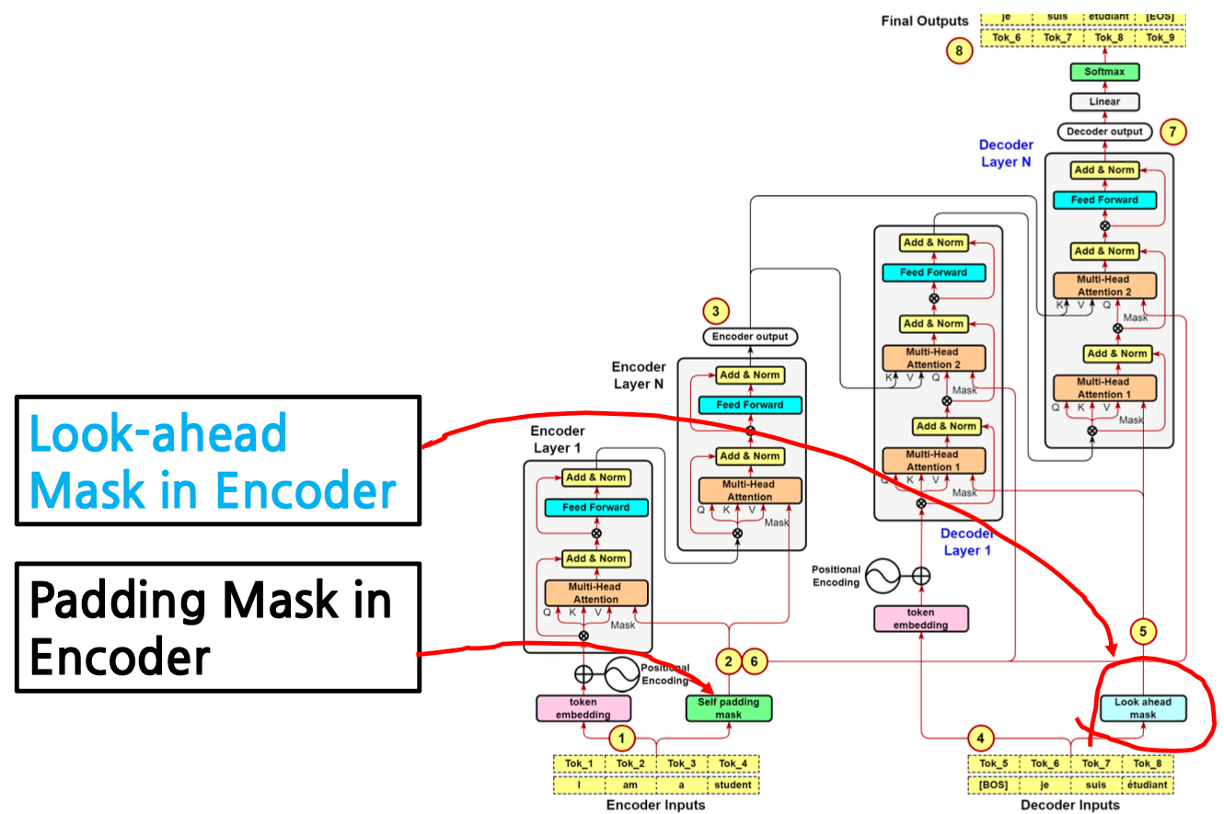
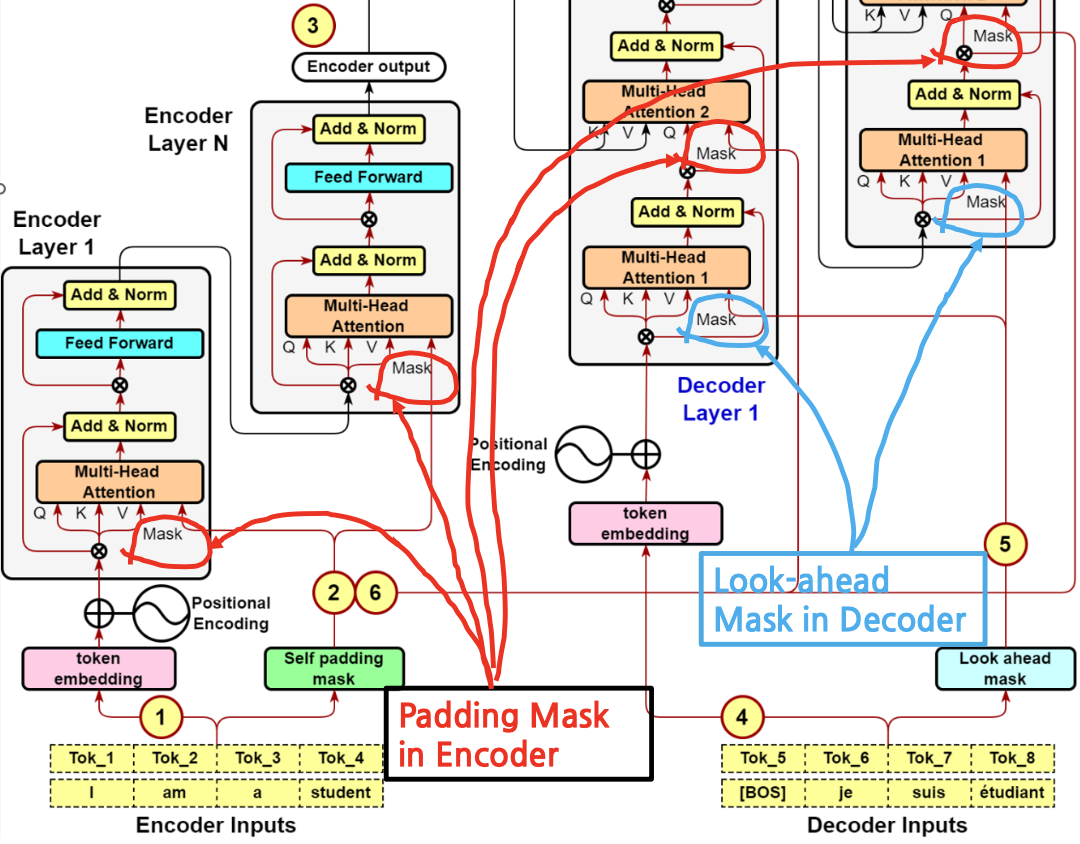
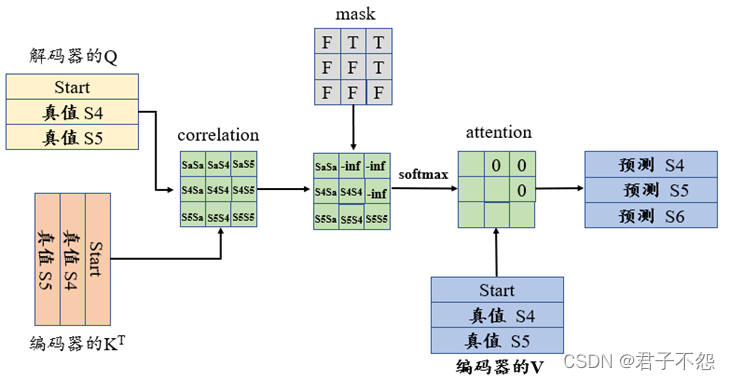
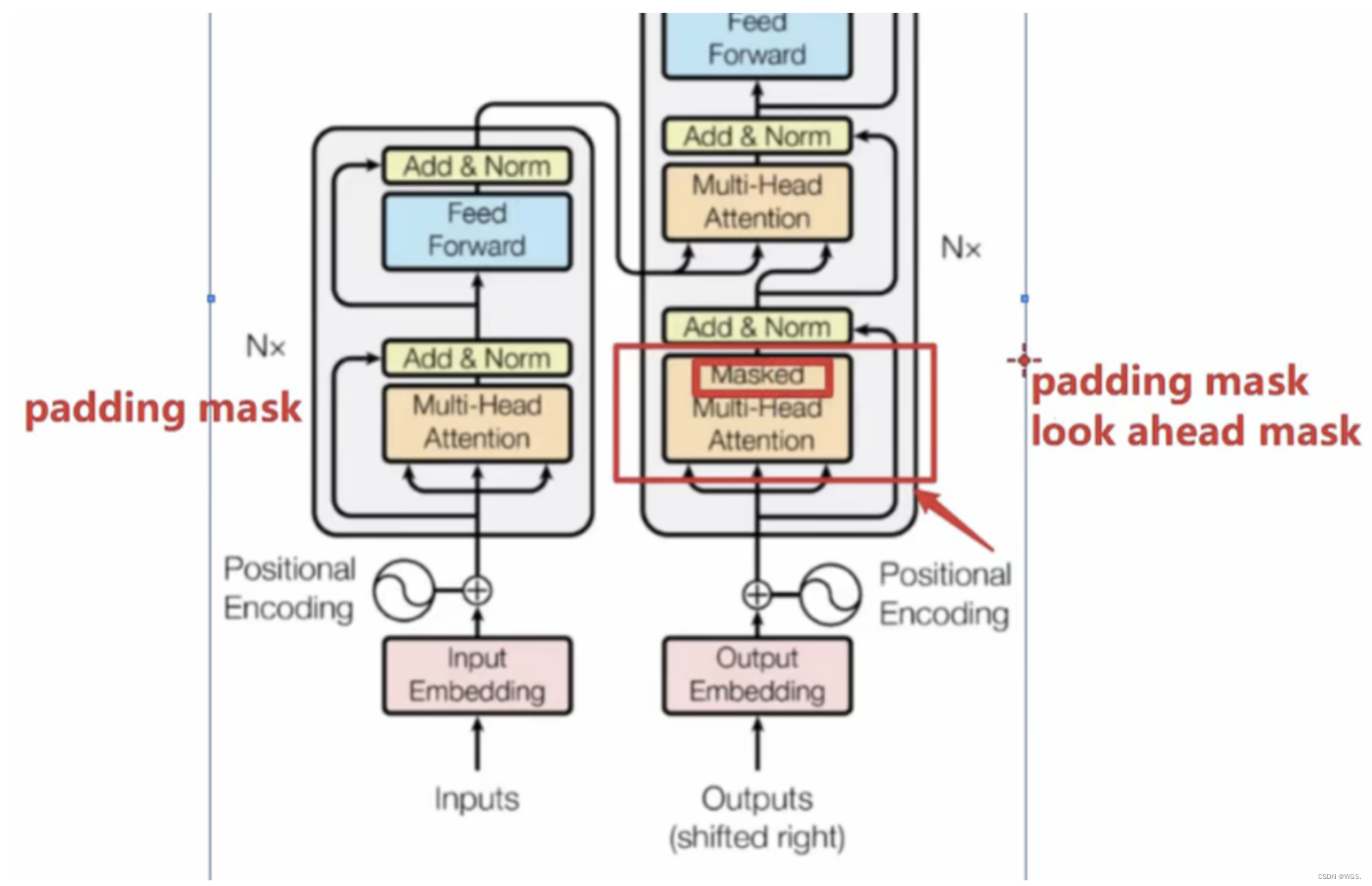
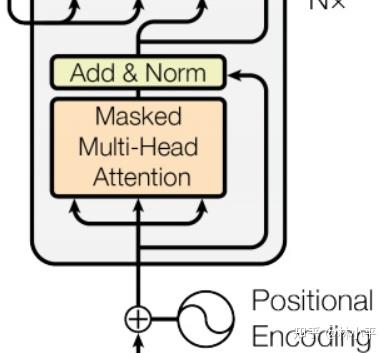
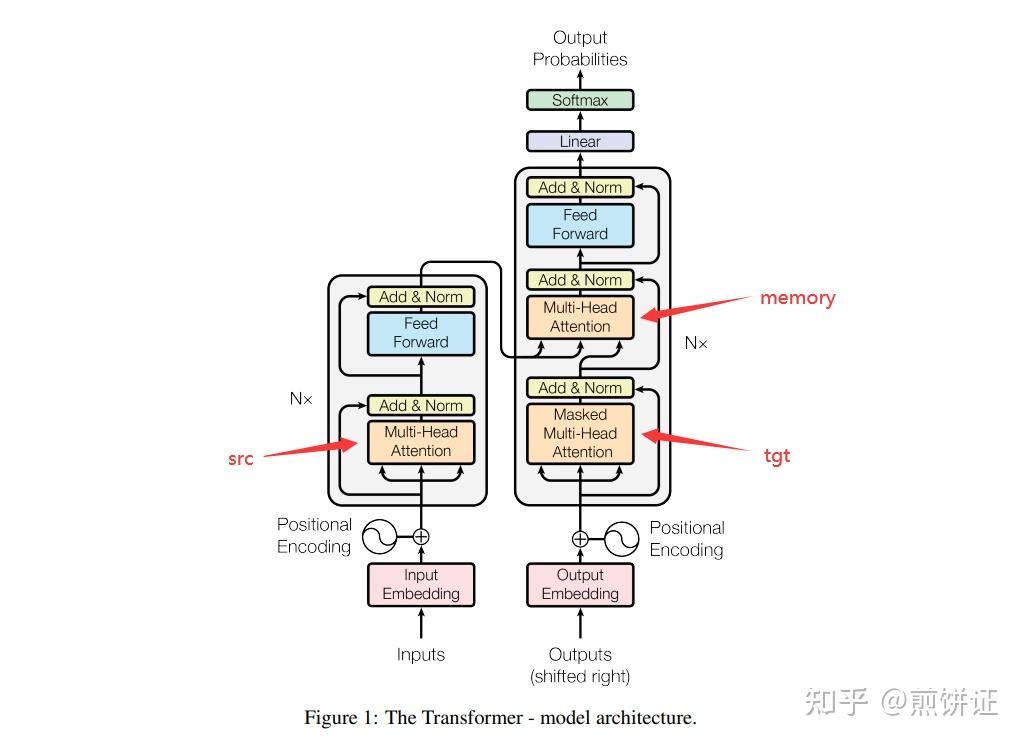
Padding and Look-Ahead Mask in the Transformer Decoder
All the questions about Transformer model answered Part 5: The Padding ...
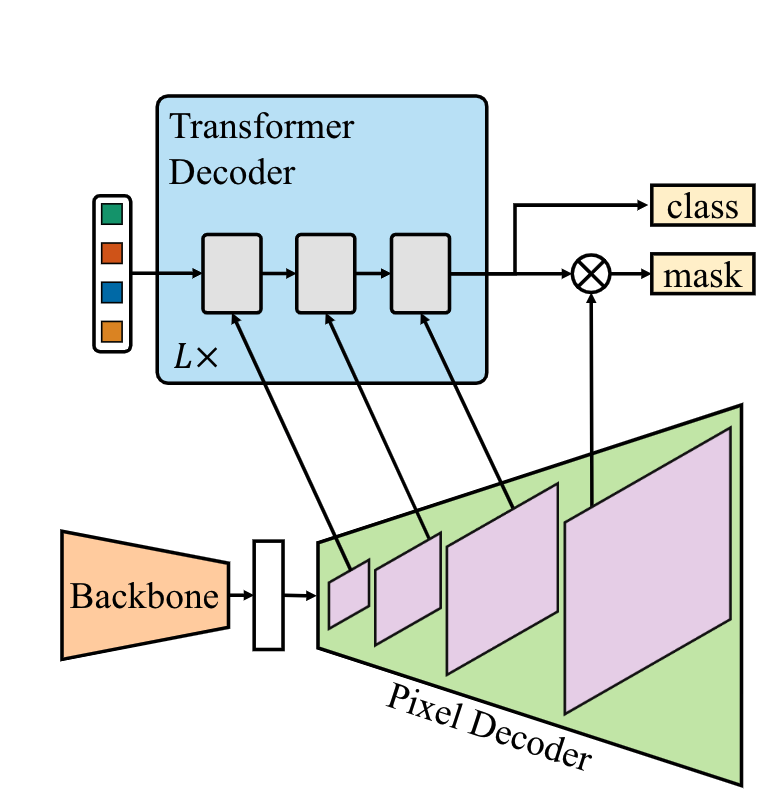
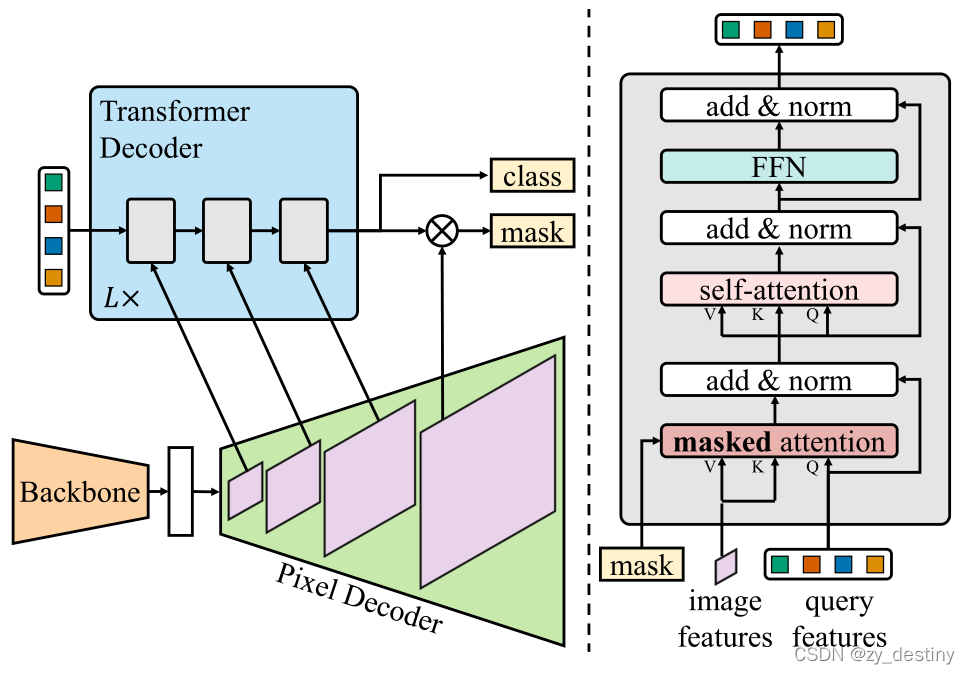
Masked-attention Mask Transformer for Universal Image Segmentation ...
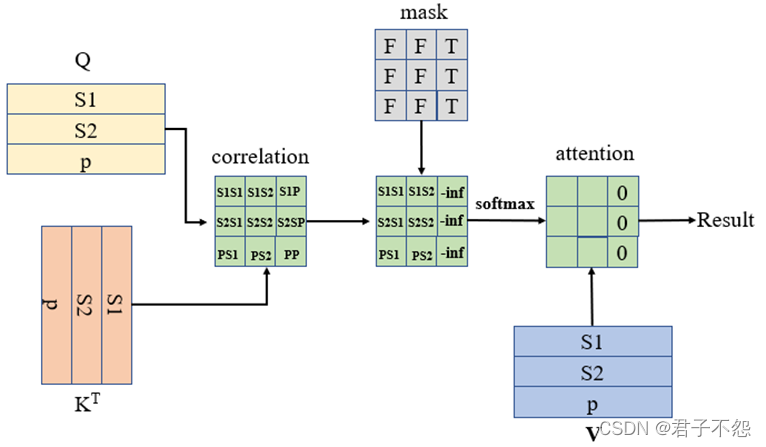
Scaled-dot product with role mask or padding mask. | Download ...
Robot transformer Inspired Masks | Transformers mask printable, Autobot ...
Transformer 源码中 Mask 机制的实现 - 虾野百鹤 - 博客园
【论文笔记】Mask2Former: Masked-attention Mask Transformer for Universal ...
【Mask2Former】Masked-attention Mask Transformer for Universal Image ...
Coloring Transformer Mask Printable Print Out These Autobot
Transformer模型-学习笔记_transformer padding mask-CSDN博客
Transformer结构解析(附源代码)_transformer padding mask-CSDN博客
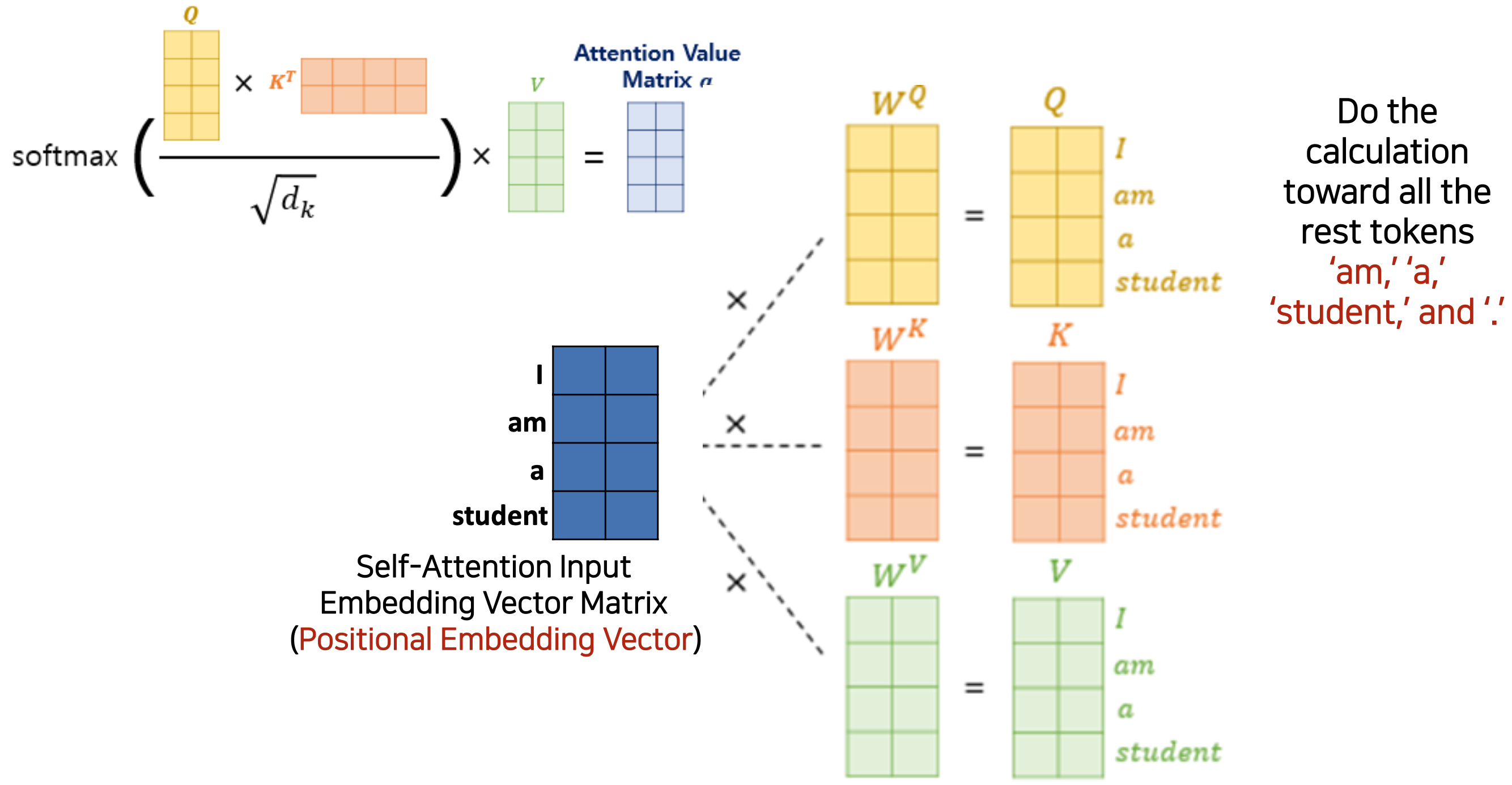
Chapter 4. Attention Value Matrix in Transformer
GitHub - ebsc0/transformer: Transformer implementation from Attention ...
transformer 中: self-attention 部分是否需要进行 mask?-极市开发者社区
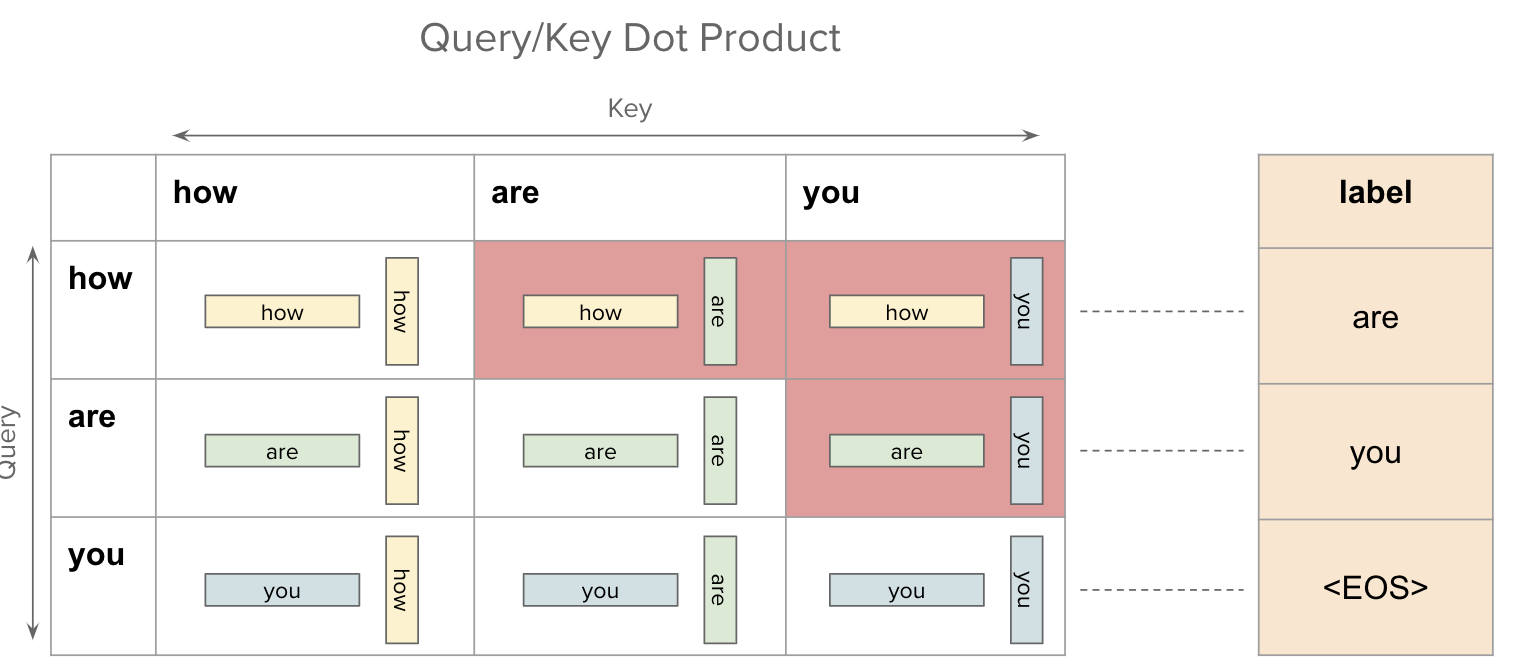
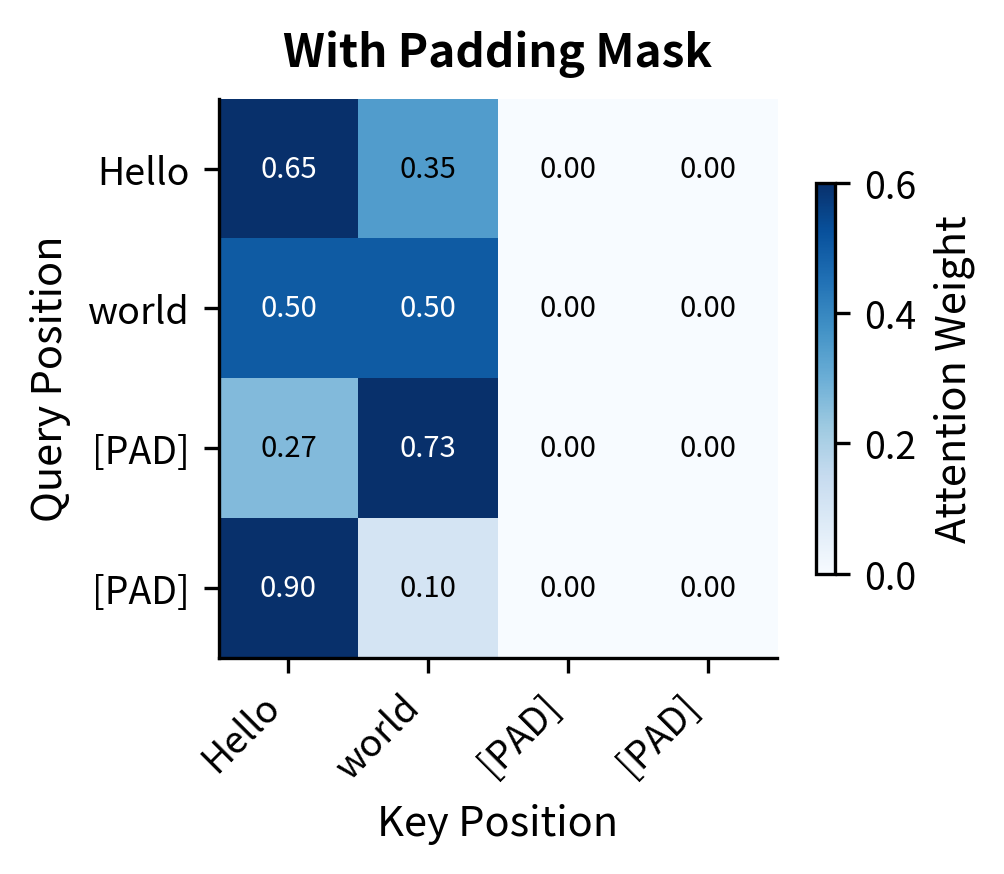
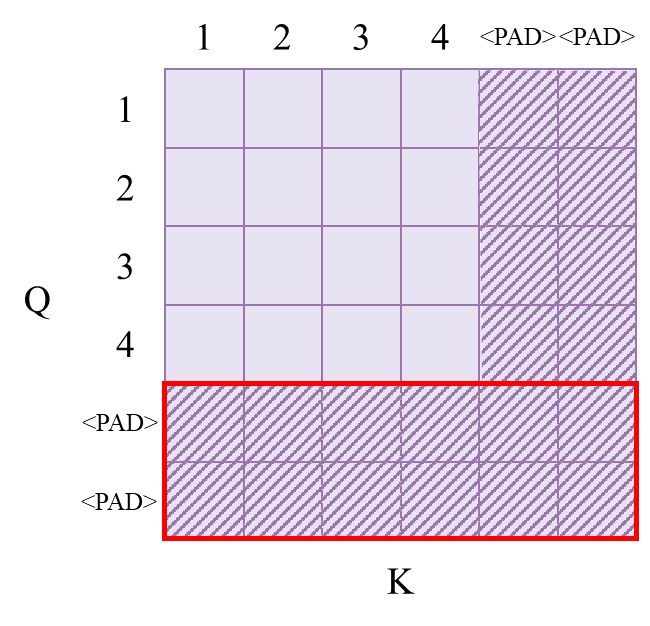
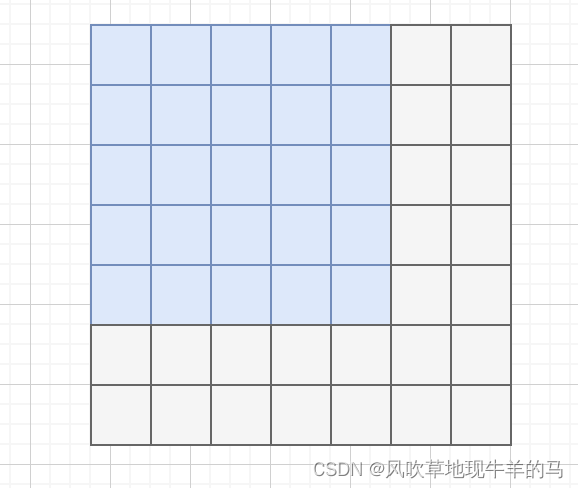
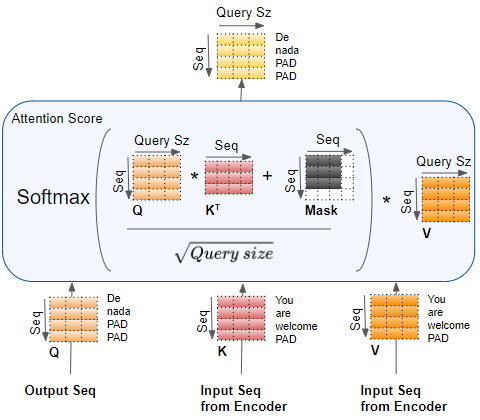
Intuition about the application of padding masks and look-ahead masks ...
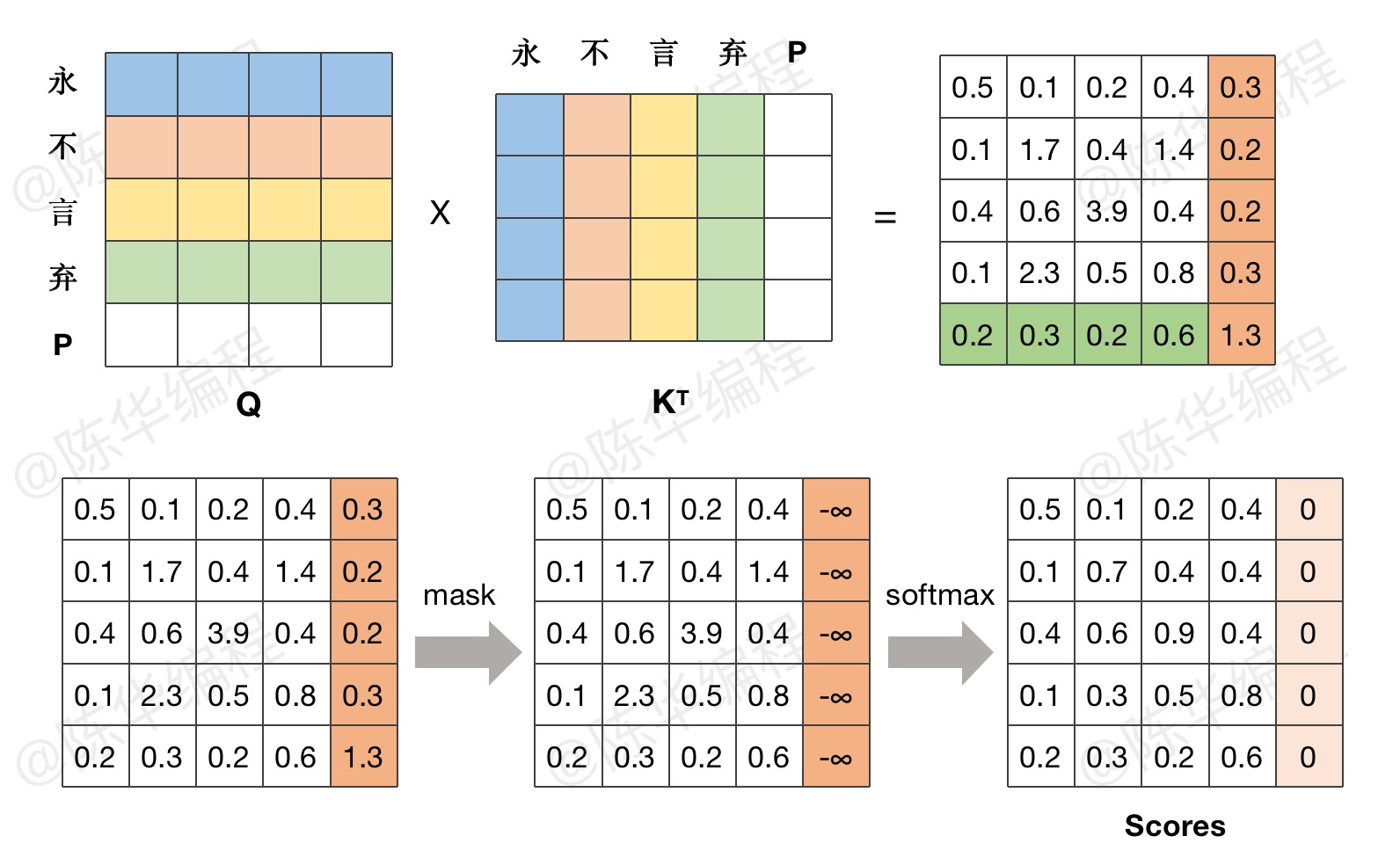
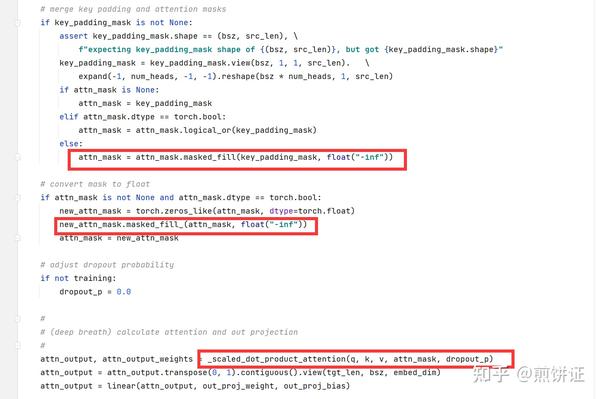
Transformer P8 Attention处理Key_Padding_Mask - 陈华编程
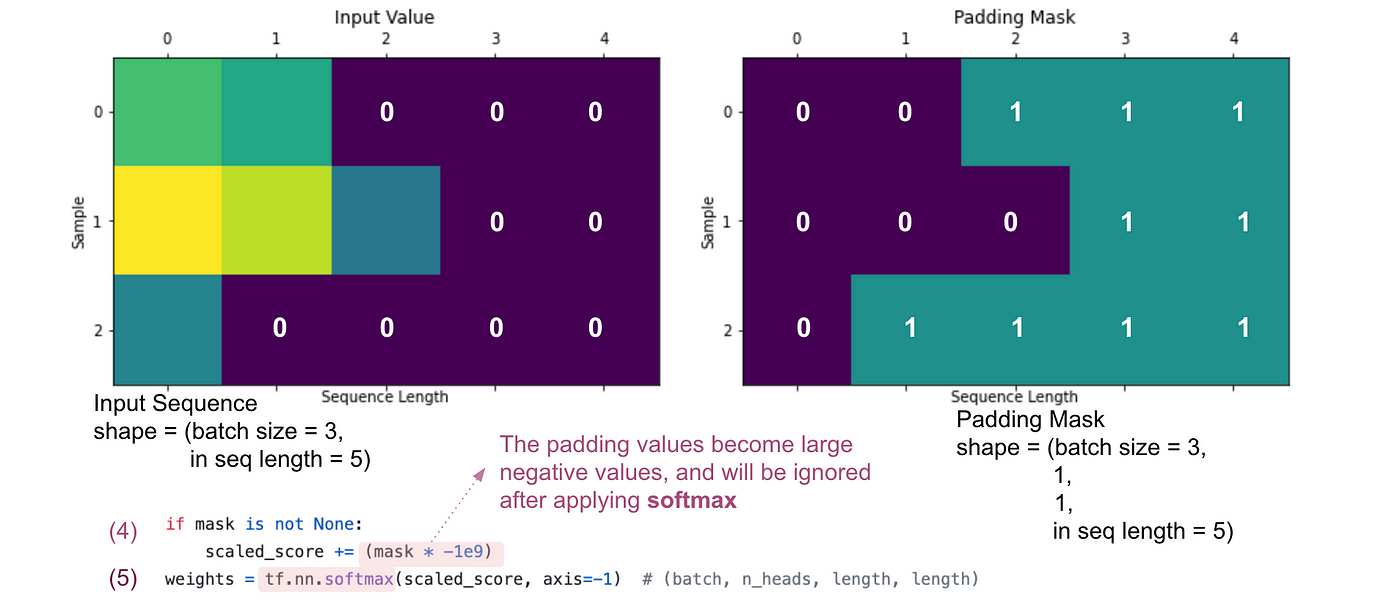
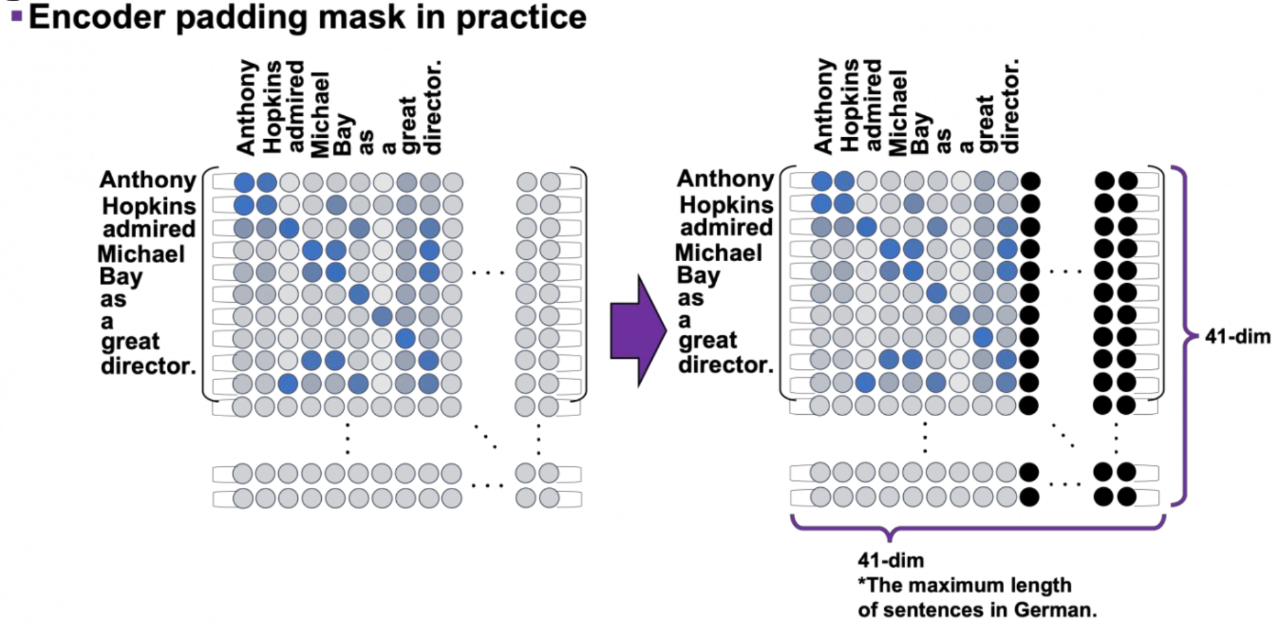
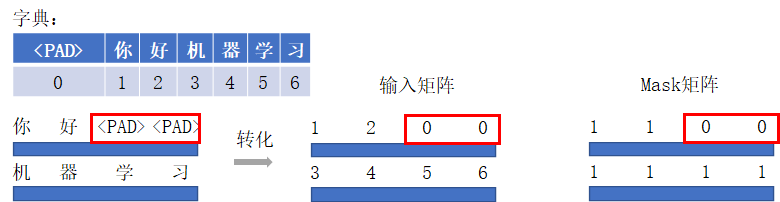
[机器学习]对transformer使用padding mask - 溡沭 - 博客园
Hasbro Transformers Authentics Mask Optimus Prime F3070 / F3749 | Toys ...
Hasbro Transformers Movie 7 Rise of the Beasts 2-in-1 Converting Mask ...
Learning JAX by Building Flexible Transformer Attention Masks: From ...
C5_W4_A1_transformer_subclass questions about padding and create ...
Masking in Transformer Encoder/Decoder Models - Sanjaya’s Blog
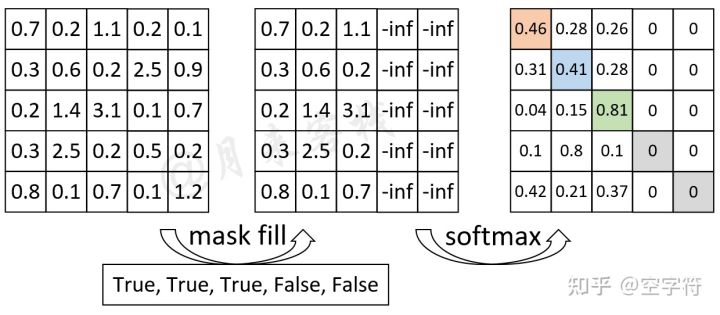
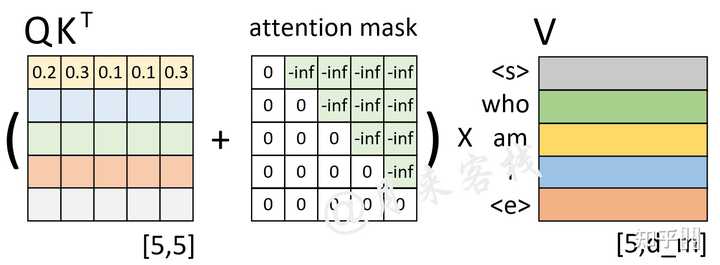
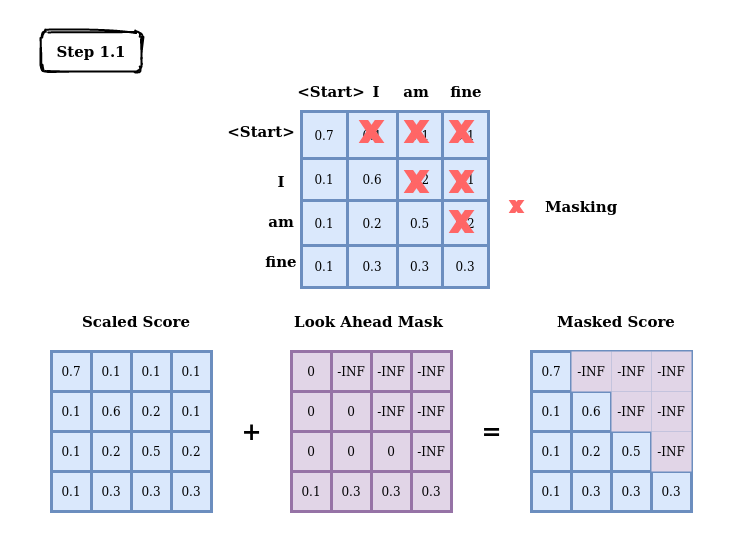
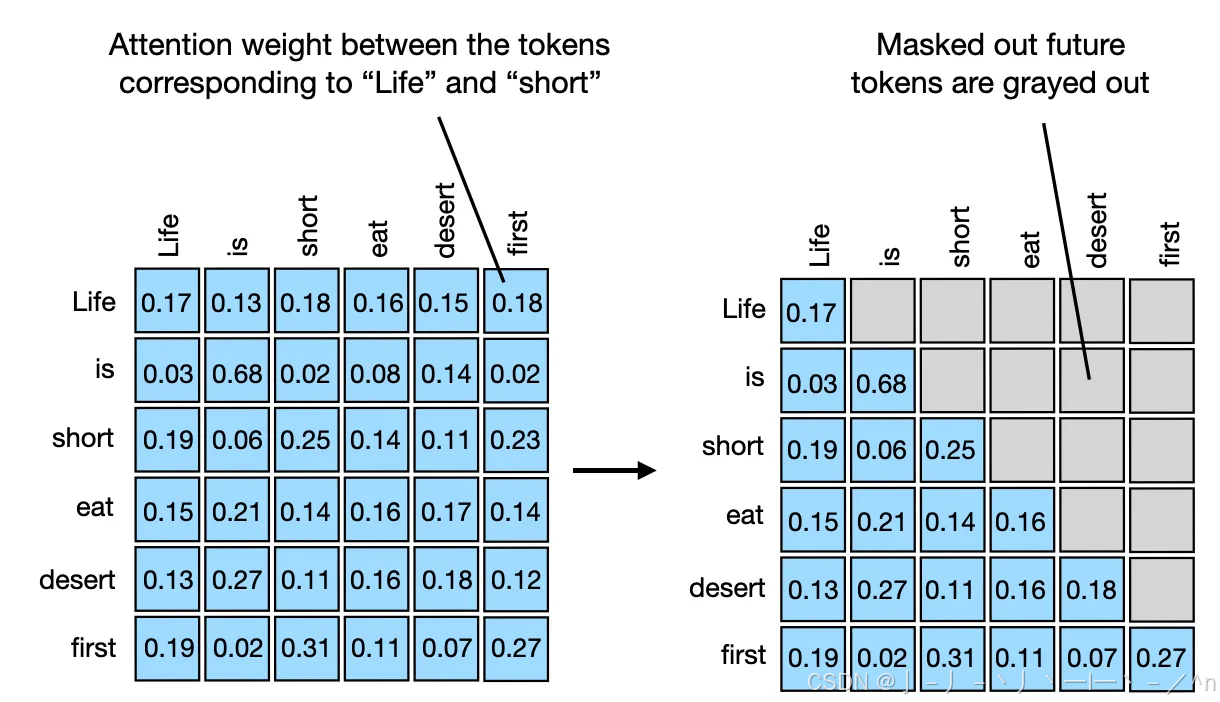
A Simple Example of Causal Attention Masking in Transformer Decoder ...
Transformers Bumblebee 2-in-1 Converting Roleplay Mask - Bumps and Bottles
Transformers Age Of Extinction Bumblebee Mask
C5 W4 - Mistake in Transformer dec_padding_mask - Sequence Models ...
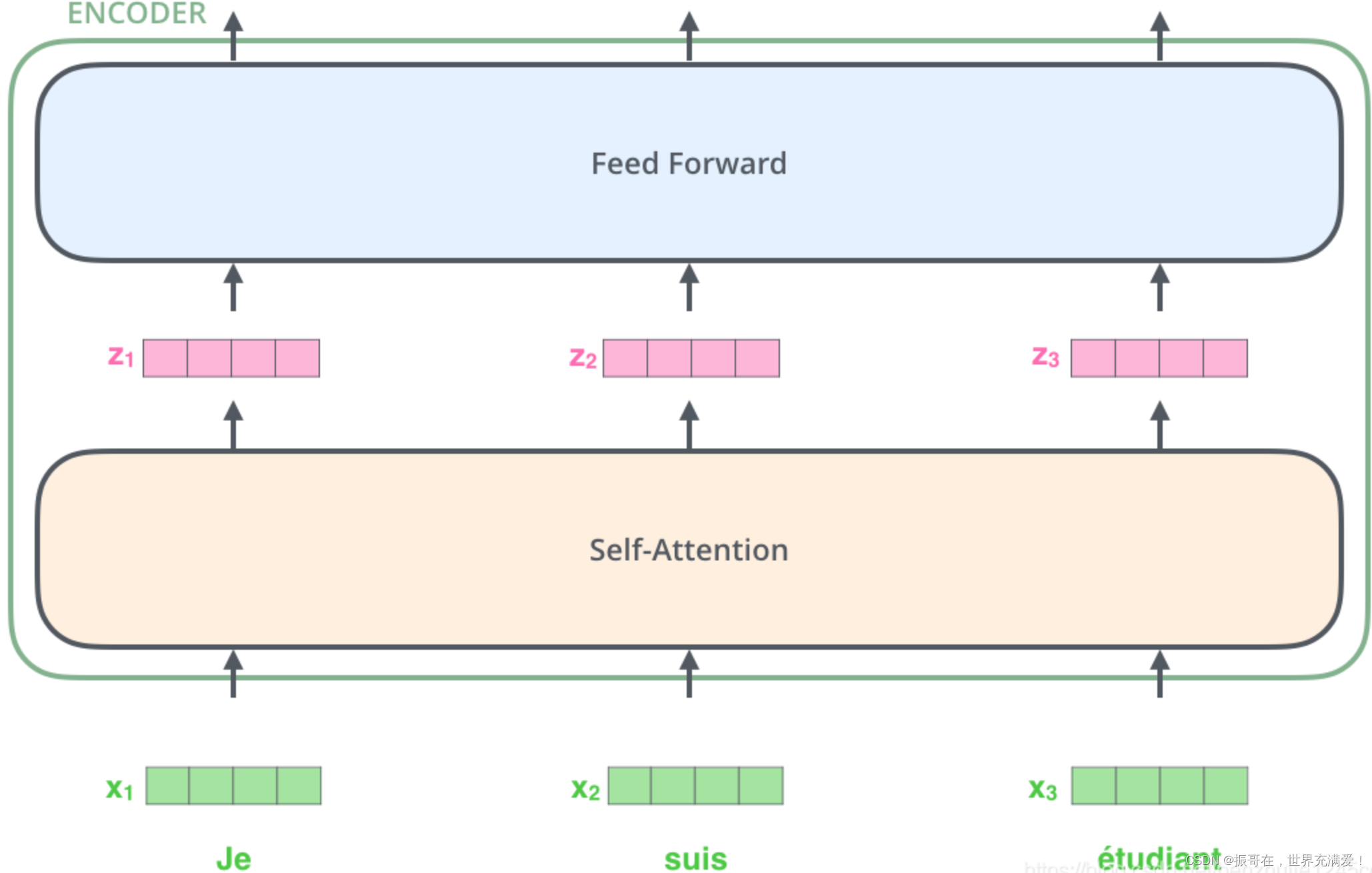
【通俗易懂】大白话讲解 Transformer - 知乎
Transformer (Attention Is All You Need) 구현하기 (2/3) | Reinforce NLP
Transformer Part 1: Build | Minibatch AI
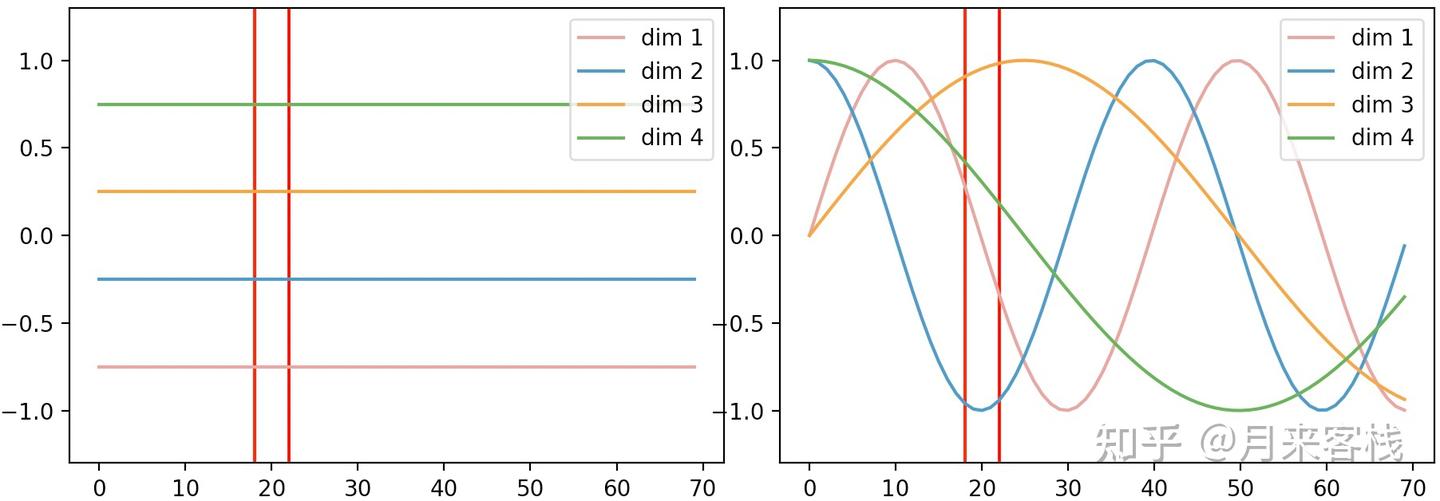
Positional encoding, residual connections, padding masks: covering the ...
[NLP] Transformer (2)
Transformer - 知乎
Transformer Masks | Transformer activities
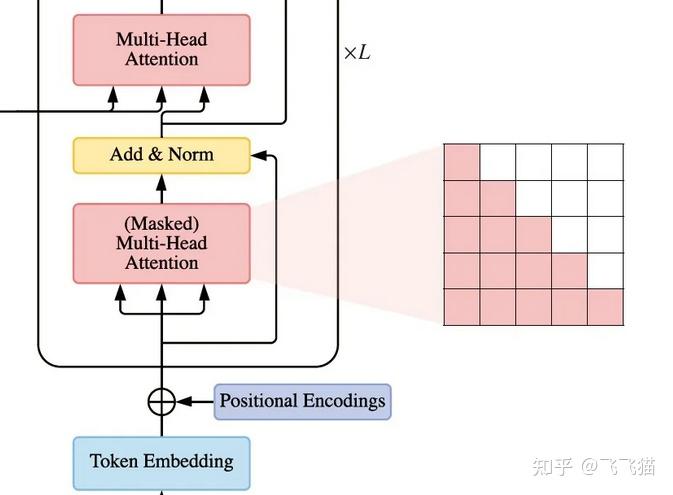
Transformer Encoder/Decoder结构中的掩码Mask介绍 - 知乎
Transformers 4 Bumblebee Mask
Python----循环神经网络(Transformer ----Attention中的mask)-CSDN博客
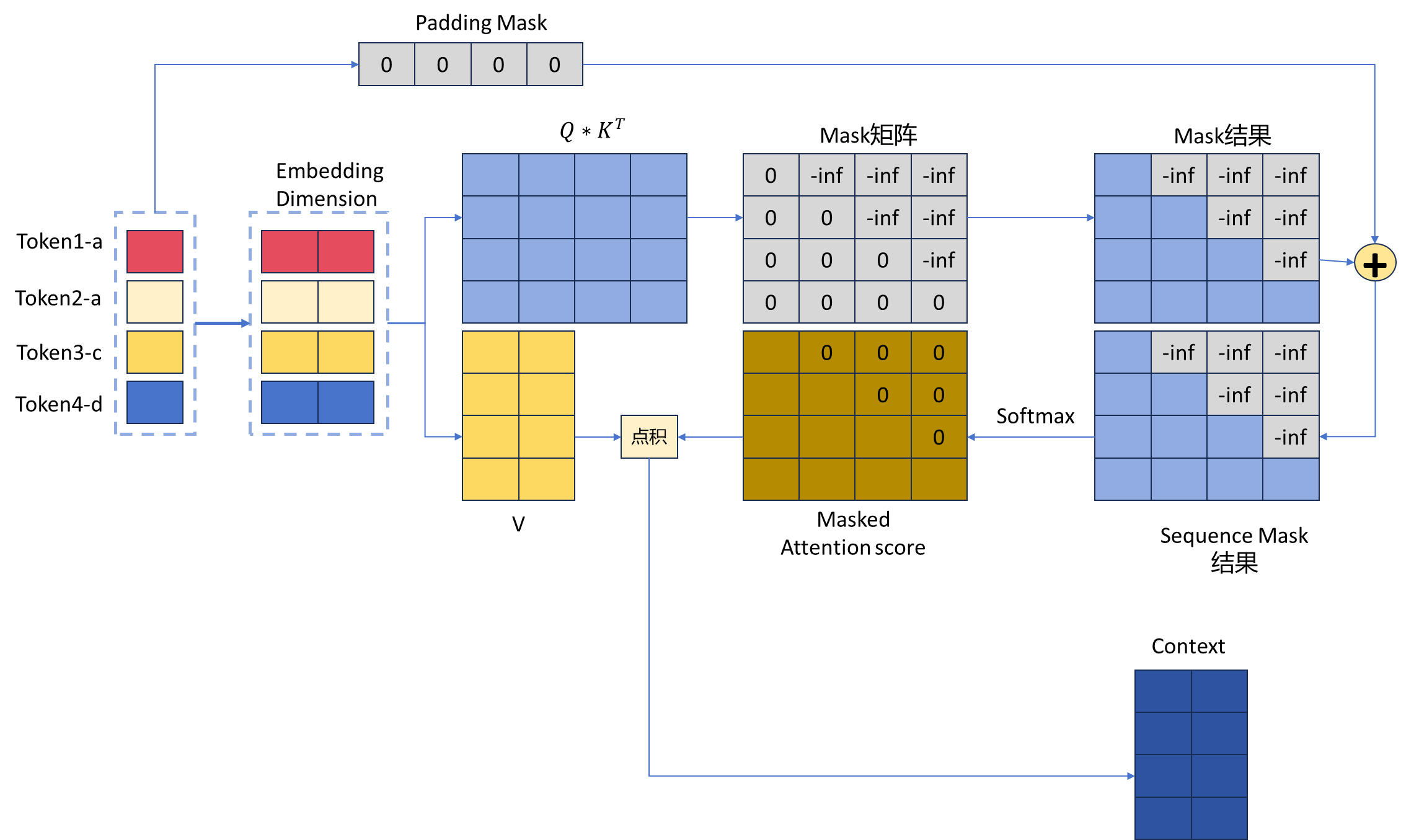
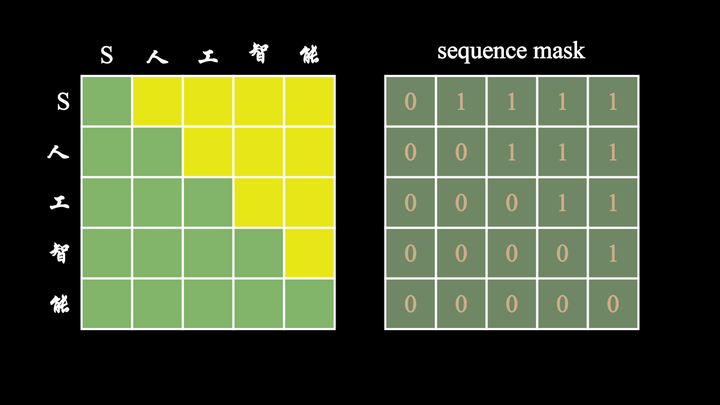
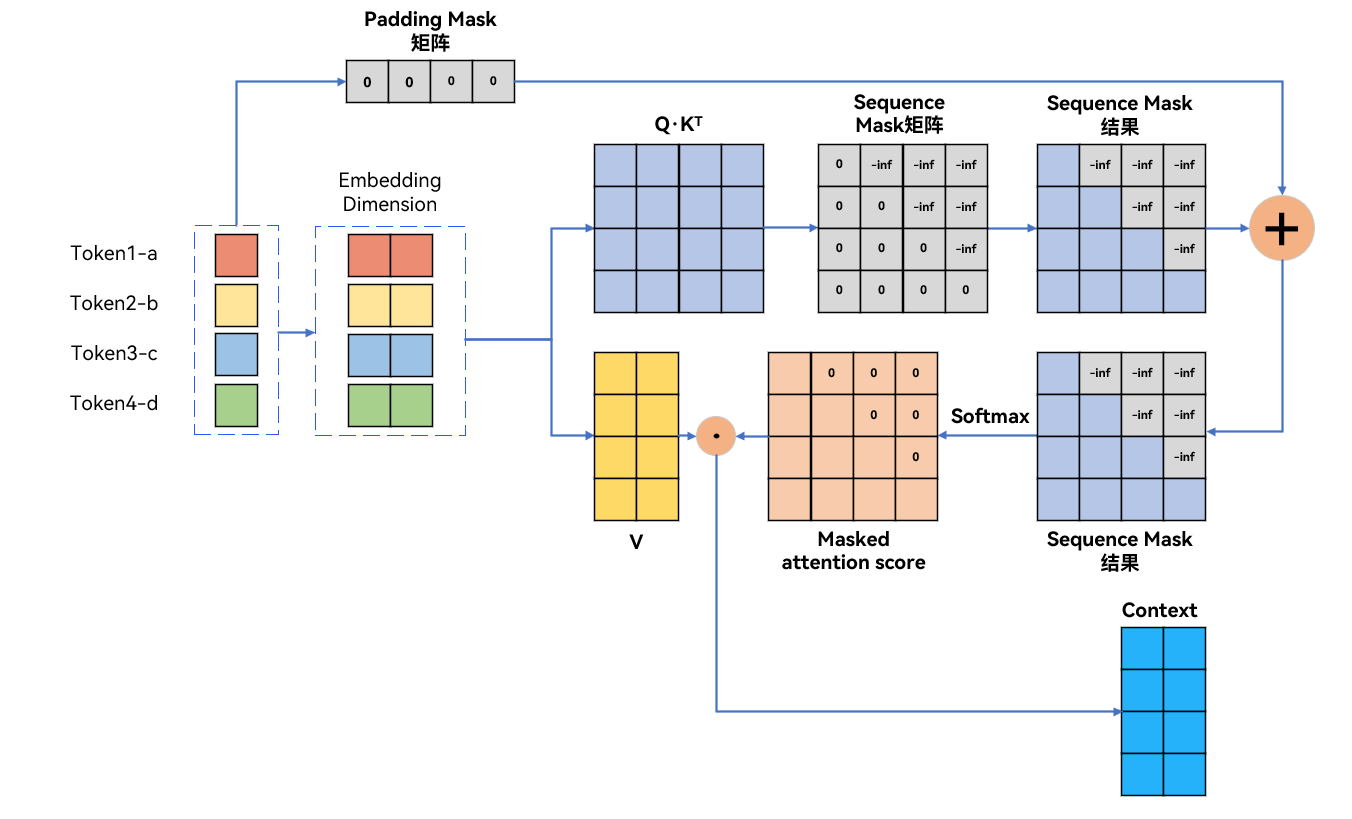
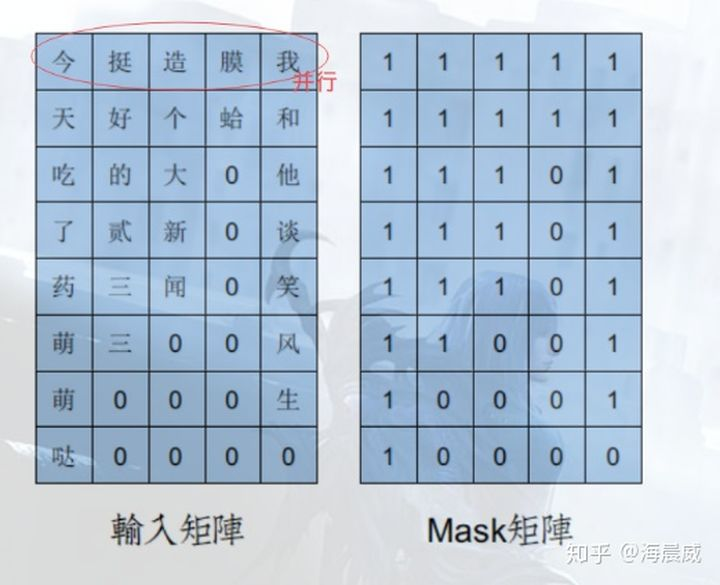
图文详解transformer模型—pad mask与sequence mask掩码张量详解 - 知乎
transformer中: self-attention部分是否需要进行mask? - 知乎
Attention Masking: Controlling Information Flow in Transformers ...
Transformer相关——(7)Mask机制 | 冬于的博客
Brandclub - Transformers: Rise of the Beasts Optimus Primal Converting ...
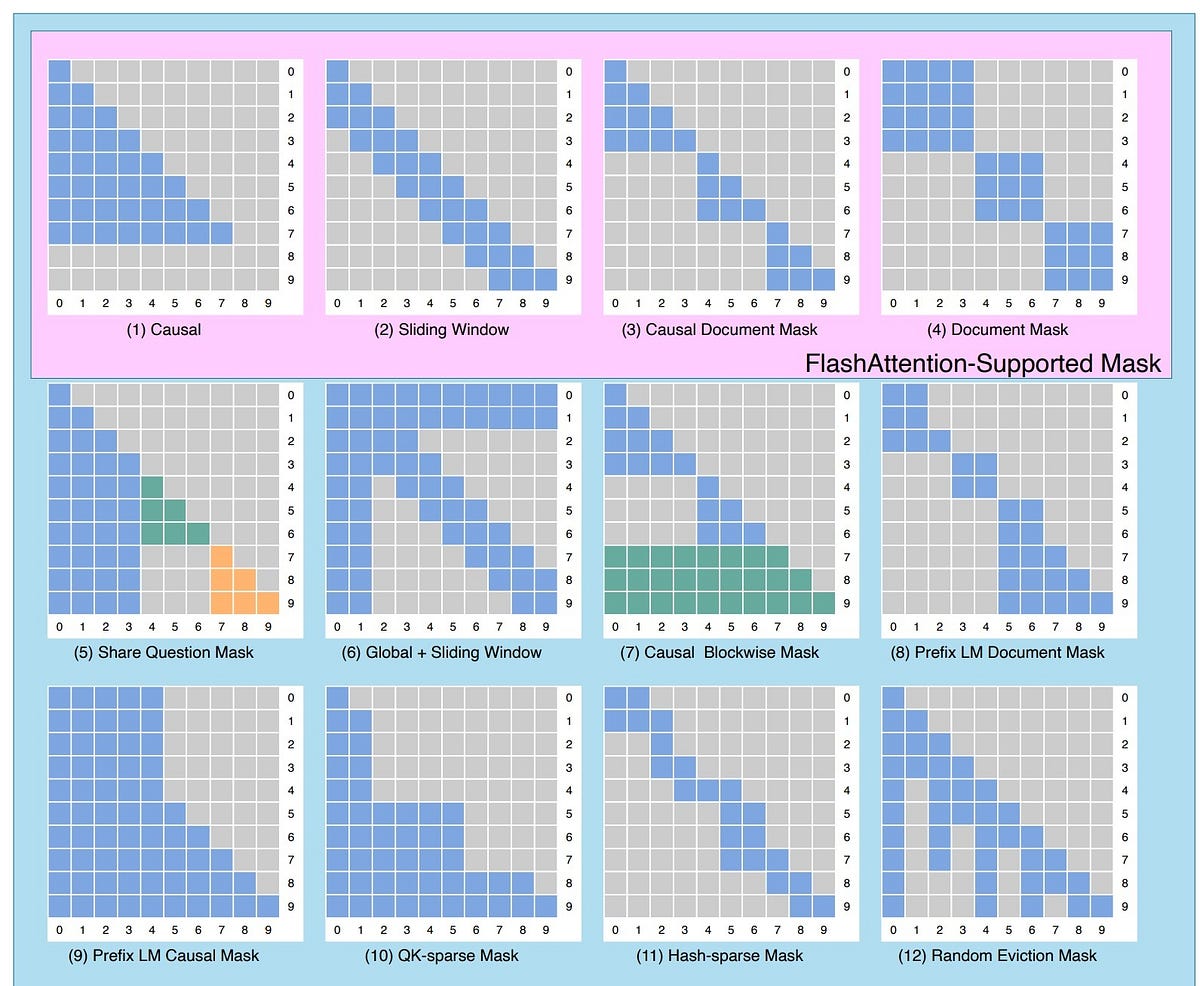
4D masks support in Transformers
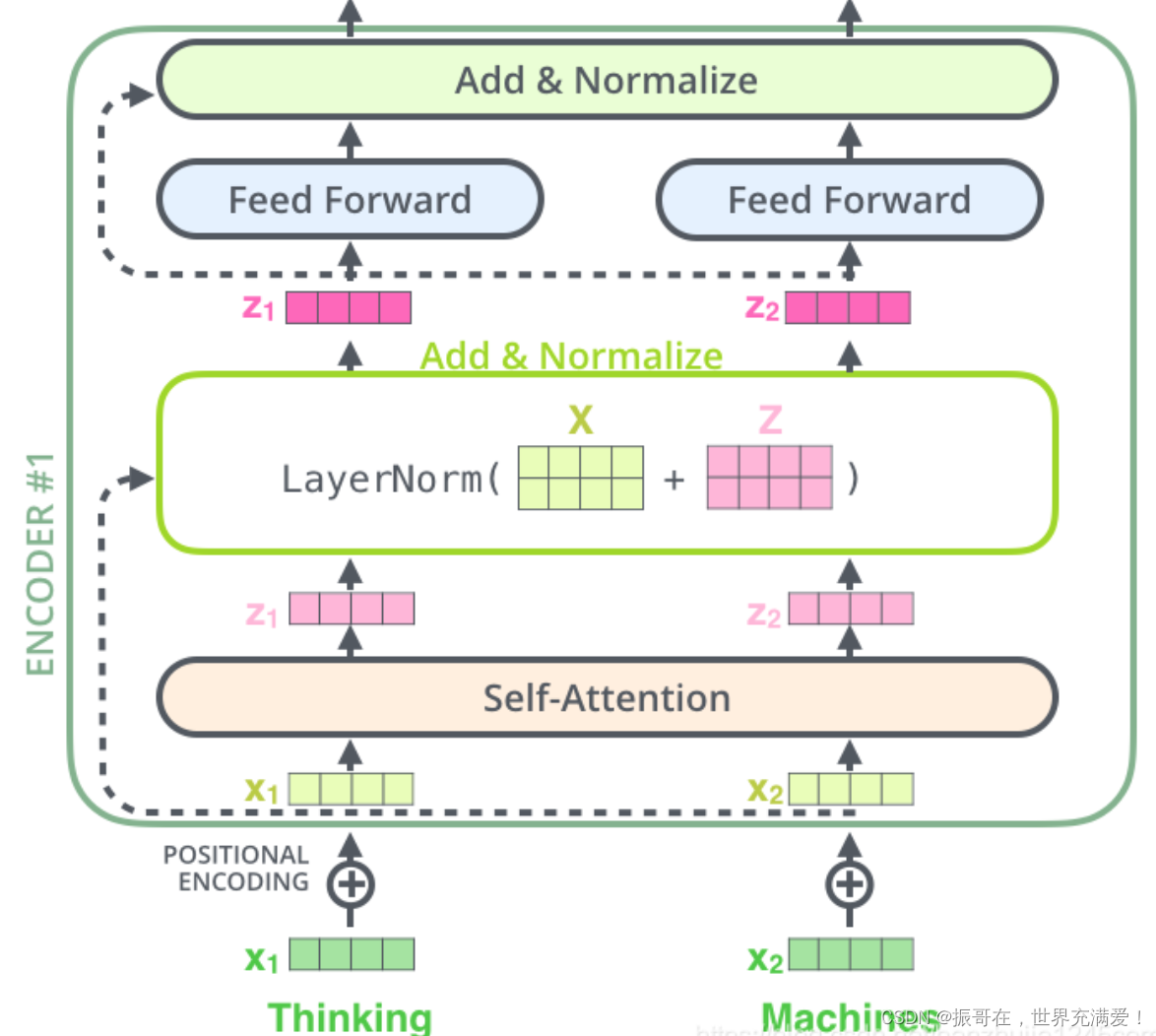
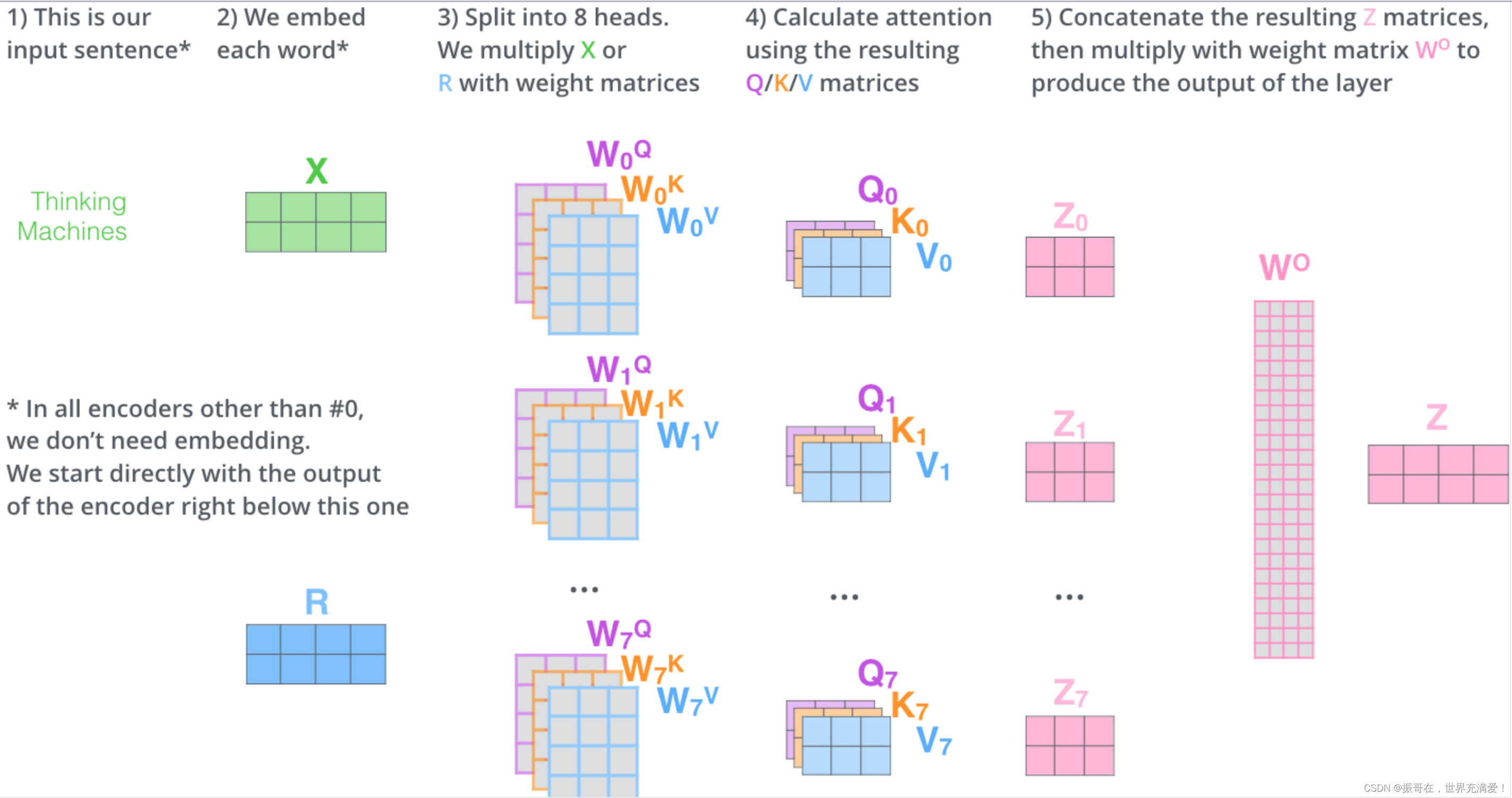
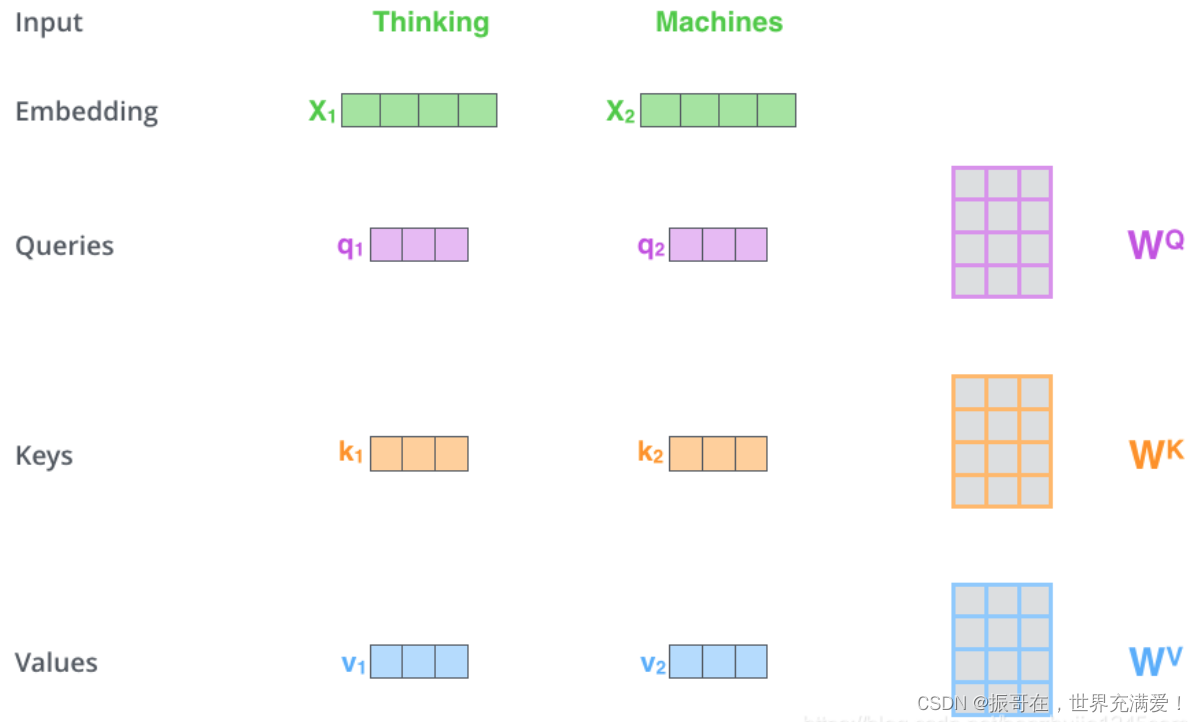
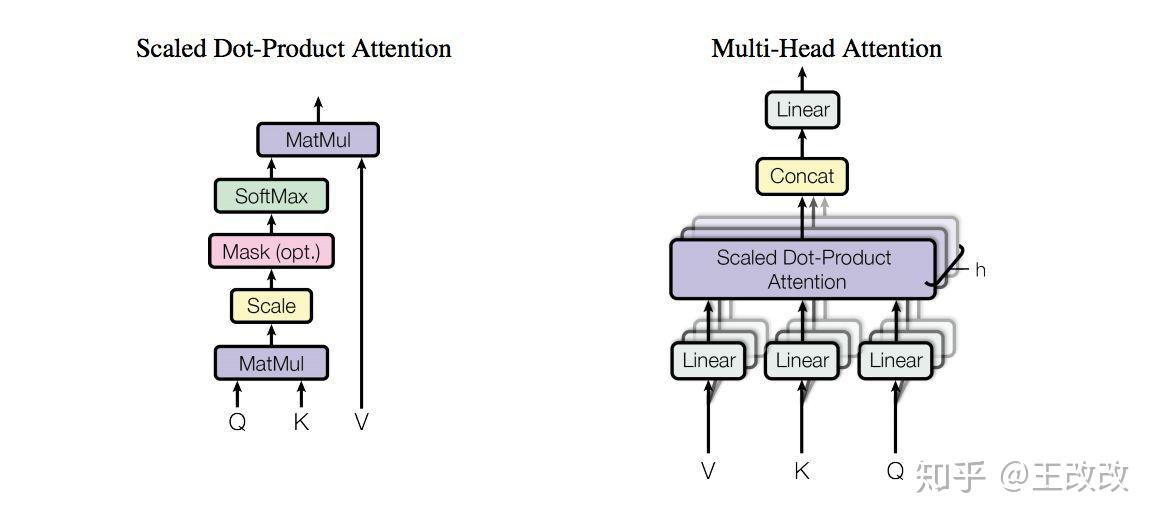
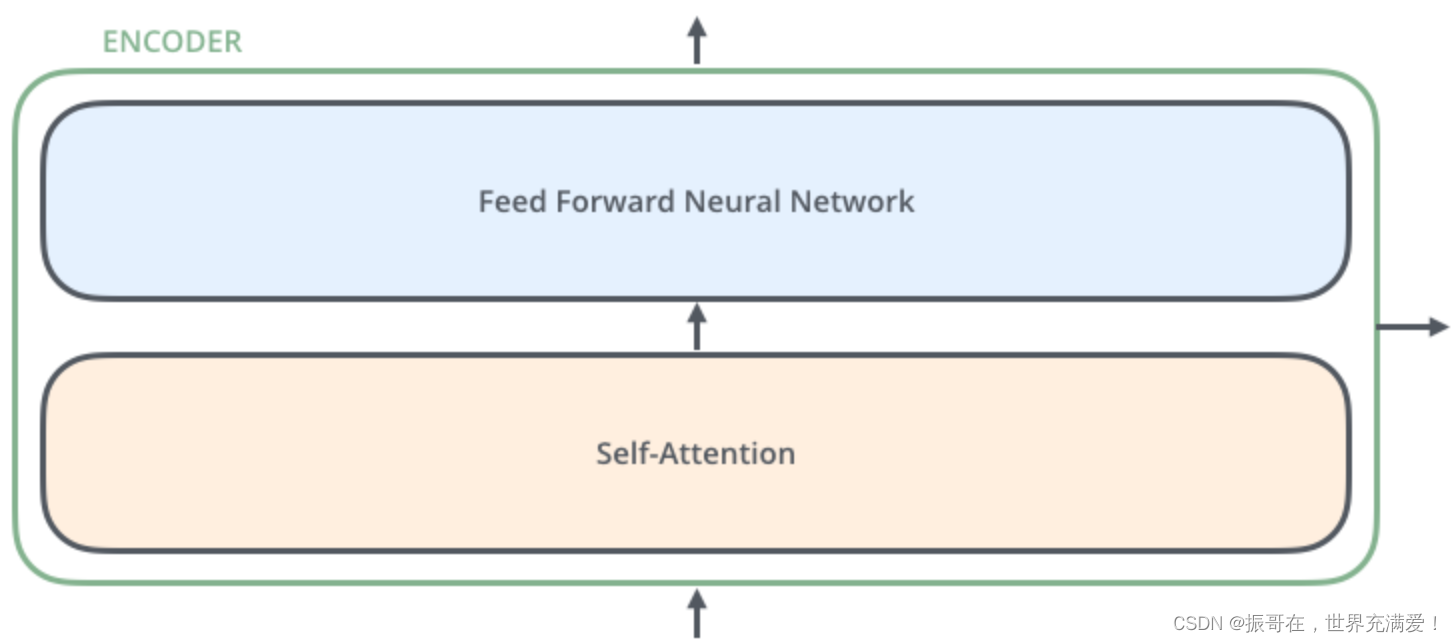
Transformers — Visual Guide
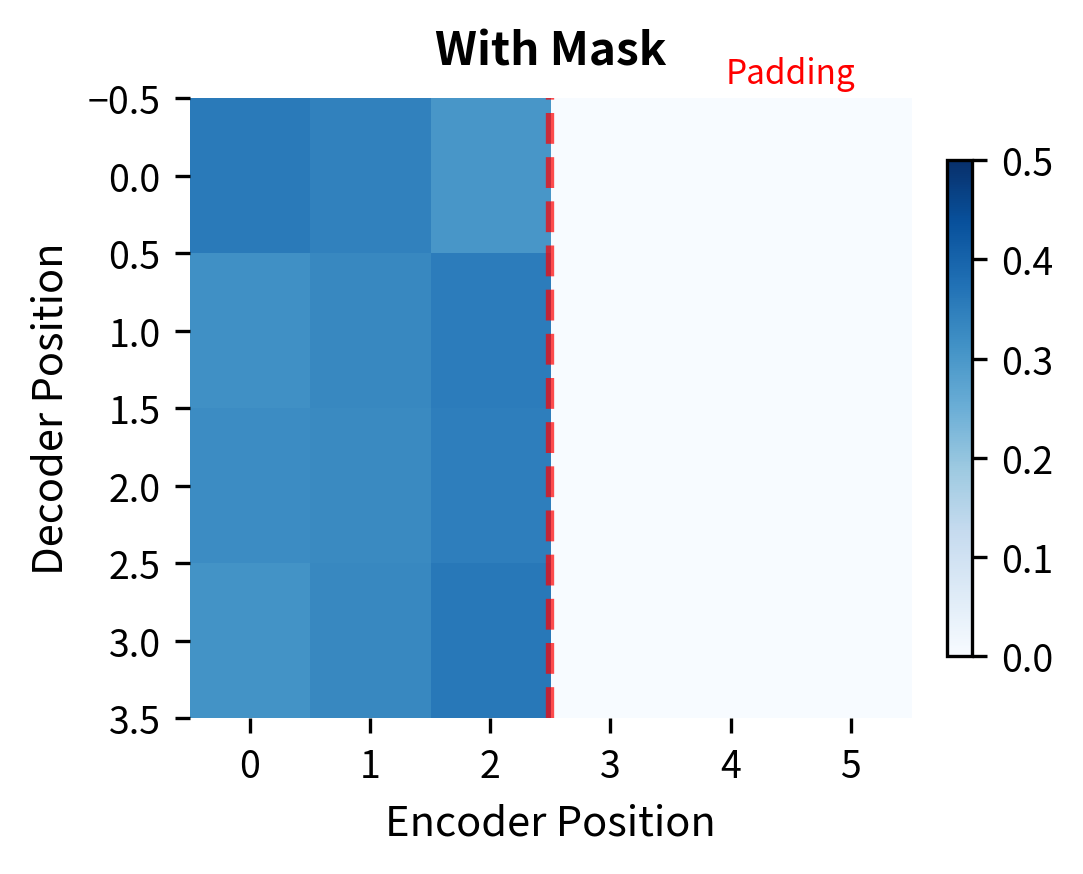
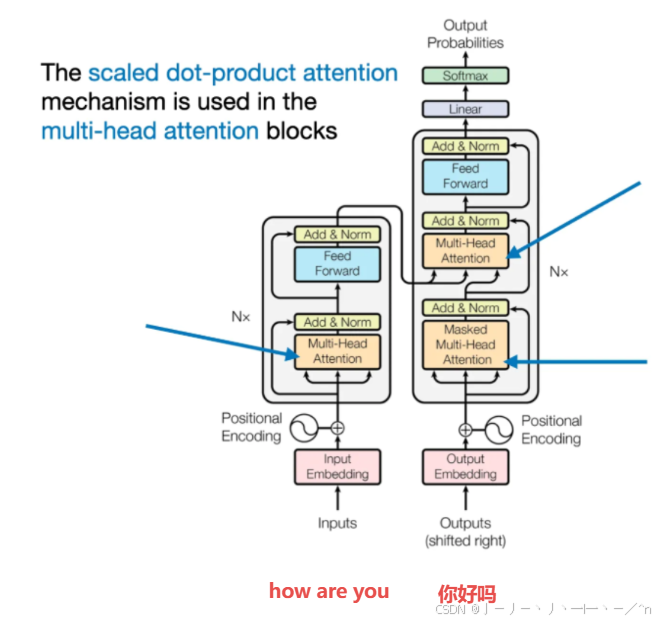
Cross-Attention: Connecting Encoder and Decoder in Transformers ...
Generation of the Extended Attention Mask, by multiplying a classic ...
小杰-自然语言处理(eleven)——transformer系列——Attention中的mask_attention mask-CSDN博客
保姆级讲解Transformer_位置编码在序列padding前还是pading后与序列相加-CSDN博客
Understanding_Transformers
【手撕系列】手撕Transformer-CSDN博客
Transformers Authentic Masks for Kids, Assortment | Party Expert
【手撕Transformer】Transformer输入输出细节以及代码实现(pytorch)-CSDN博客
动图图解Transformer及其工程领域应用(NLP外)_tranformer动图-CSDN博客
pytorch nn.Transformer的mask理解 - 知乎
Transformers Revenge of the Fallen Paper Masks | Fiesta de los ...
Transformer模型-encoder编码器,padding填充,source mask填充掩码的简明介绍_transformer ...
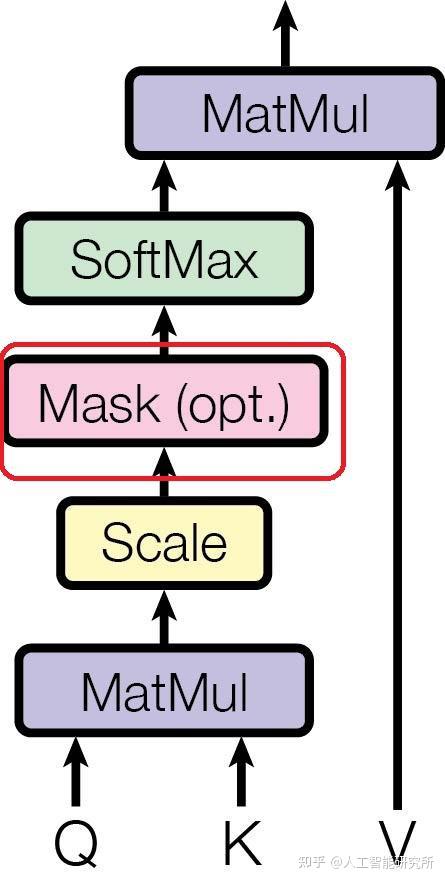
模型结构|解读transformer模型中三种attention和mask(一)_casual mask-CSDN博客
【课程总结】day19(中):Transformer架构及注意力机制了解 - 一起AI技术
Transformer详解 - 知乎
transformer的原理_transformer原理-CSDN博客
极简翻译模型Demo,彻底理解Transformer - 知乎
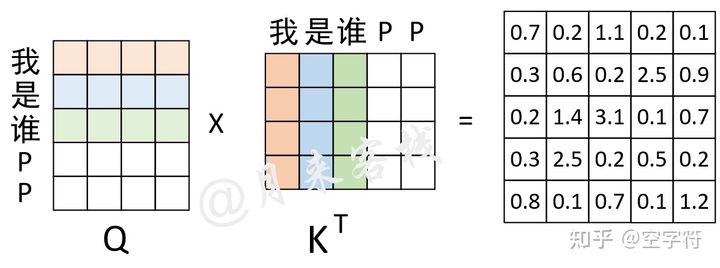
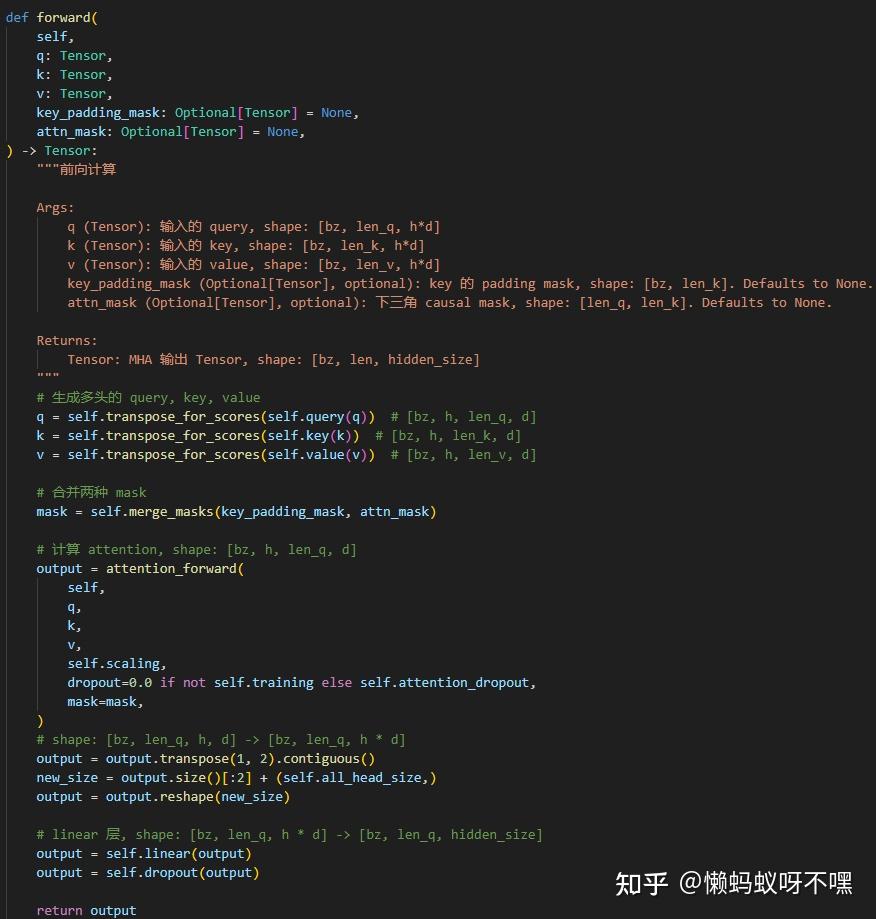
【Pytorch】Transformer中的mask - 知乎
GPU底层优化 | 如何让Transformer在GPU上跑得更快?-CSDN博客
nn.TransformerEncoderLayer中的src_mask,src_key_padding_mask解析_nn ...
手撕 Transformer(一):模型实现 - 知乎
Transformer详细解读和代码实现 - DataSense
学习Transformer弄懂这7个问题就够了 - 知乎
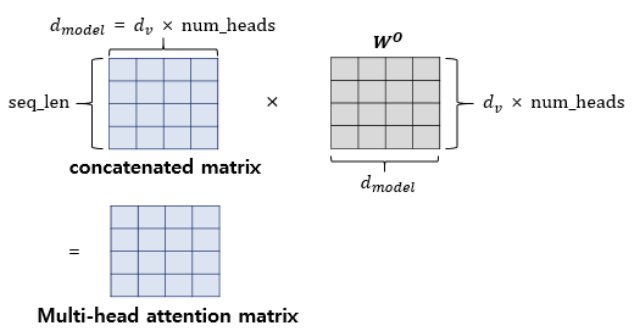
Transformers Explained Visually - Multi-head Attention, deep dive ...
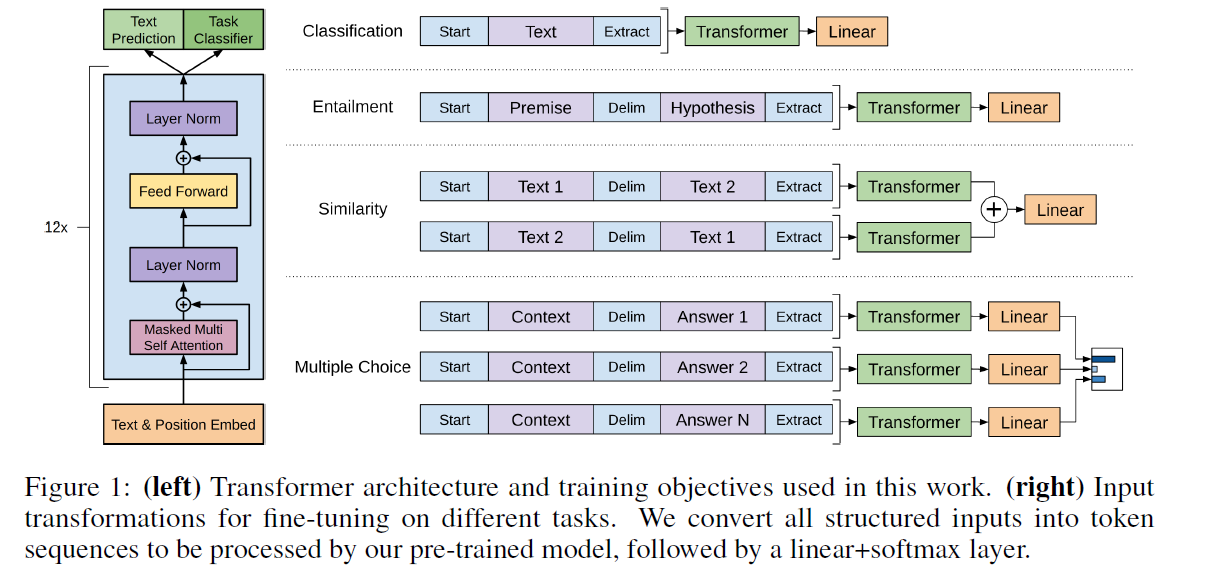
Transformer: All the Ambiguities of the Paper Explained - Part 3 - The ...
Transformers Rise of the Beasts Converting Masks Wave 1 Case
Building Transformers from Scratch in PyTorch: Theory, Math, and Full ...